0 引言
随着城市化与交通基建的推进,隧道工程在现代交通网络中愈发关键。截至2024 年底,中国大陆地铁、铁路等领域的隧道建设规模与重要性均显著提升。但复杂地质条件、施工扰动及长期服役环境等问题,使得隧道工程面临显著的不确定性风险,其核心难题本质上是高维非线性问题。传统方法(如解析法、有限元模拟)存在数据利用率低、泛化能力弱等局限性,而机器学习(machine learning, ML) 通过挖掘海量监测数据中的隐含规律,为解决上述问题提供了新范式。其优势主要体现在自适应特征提取 、实时动态预测、时序特征提取优化和多源数据融合。
ML 具备从复杂、动态与不确定数据中提取有效规律的能力,可为隧道工程提供及时、可扩展的智能决策支持。通过不断更新训练数据,ML 模型可以适应不同地质条件和施工工况,为隧道工程全生命周期管理提供支持。但ML 在隧道工程中的应用仍面临数据质量差、模型可解释性低、泛化能力不足等挑战,需要进一步研究和改进。
近年来,关于ML 在隧道工程中应用的综述类文献,多聚焦于隧道工程领域某一具体问题展开概述与分析,缺乏对全生命周期技术链条的系统性梳理。例如: Kuang 等、Zhou 等聚焦隧道缺陷检测与结构健康监测,重点分析ML 算法在裂缝、渗漏识别及实时监测中的性能与应用; 杨明辉等、刘耀儒等围绕隧道施工参数预测与风险管控,深入探讨ML 在地表沉降预测、围岩感知及地质灾害预警中的实践; 陈湘生等 、Shan 等从多场景综合应用视角,梳理ML在盾构设备状态监测、地质参数反演、病害诊断等领域的应用。上述研究虽对特定隧道类型的掘进过程,或掘进与运营阶段的局部问题具有明确分析价值,但均局限于单一隧道类型或局部技术环节,且未深入探究隧道工程围岩识别-掘进优化-健康监测3 大核心环节的内在逻辑关联与协同作用机制,难以支撑隧道工程全生命周期的智能化技术体系构建。
本文针对这一研究缺口,系统综述ML 在隧道工程全生命周期中的应用进展,旨在明确当前领域研究重心与发展脉络,剖析现有研究的技术优势及待解决问题,为后续应用实践与学术研究明晰方向、提供解决思路。研究框架具体如下: 首先,基于Web of Science核心期刊数据库检索相关文献,通过科学计量分析厘清领域研究热点与演化趋势; 其次,聚焦围岩识别-掘进优化-健康监测核心技术链条,基于大量国内外文献和工程现场调研试验,将ML 在隧道工程中的应用划分为3 类(围岩识别、掘进优化和健康监测); 再次,对领域内存在的关键挑战进行分类和总结,根据关键挑战提出对应的解决方向,对跨模态数据融合、轻量化部署等前沿方向进行展望;最后,对各类方法的技术特征、工程适用性、关键挑战和发展方向进行总结,以期为推动该领域技术创新与工程落地提供参考。
1 科学计量分析
本文调研了截至2025 年4 月的隧道工程中ML技术的研究现状。基于Web of Science 核心期刊,经过筛选,共有1633 篇论文与主题相关。
选择筛选后的1633 篇论文作为文献计量分析原始数据,导出近20 余年的被引频次趋势图(见图1)。ML 在隧道工程领域的研究呈现增长态势,相关出版物数量与被引频次均逐年攀升,2019 年后增速显著加快。这一趋势反映了技术驱动与行业需求的双重作用,一方面,ML 算法的迭代升级为复杂围岩分析、掘进参数优化等难题提供了新工具; 另一方面,隧道工程规模扩大与智能化转型迫切需要数据驱动的精准决策支持。将数据导入vosviewer 软件和origin 软件绘制关键词和弦图,用于识别研究热点,如图2 所示。最流行的关键词,如ANN、ML、deep learning、tunnel 等呼应了本文综述研究的主题; 其他关键词,如prediction、surface settlement 等反映了ML 在隧道工程中的应用情况。随时间变化,各类ML 模型在隧道工程领域的演化情况如图3 所示。由图可以看出: 研究的热点和重心从传统的人工神经网络(artificial neural network, ANN)模型逐渐深化,向混合模型、深度学习(deep learning, DL)和大语言模型方向迁移。
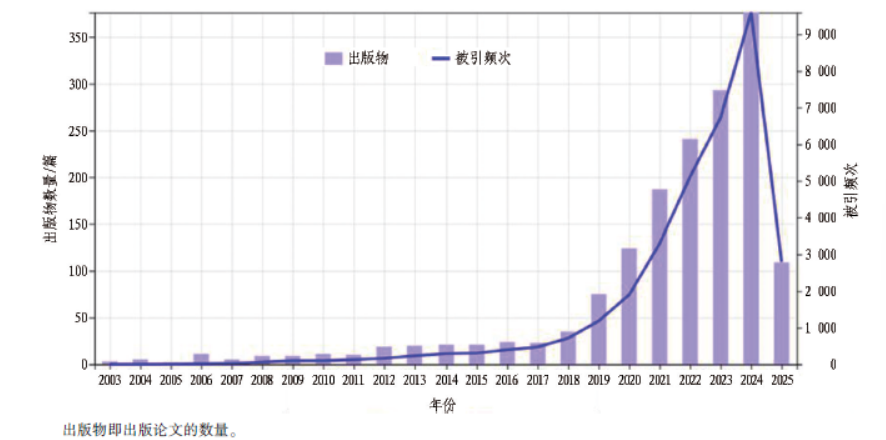
图1 被引频次时间分布图
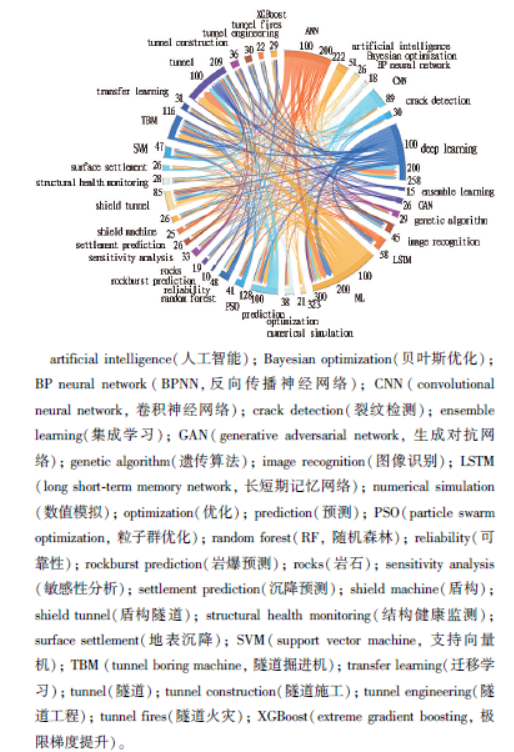
图2 关键词和弦图
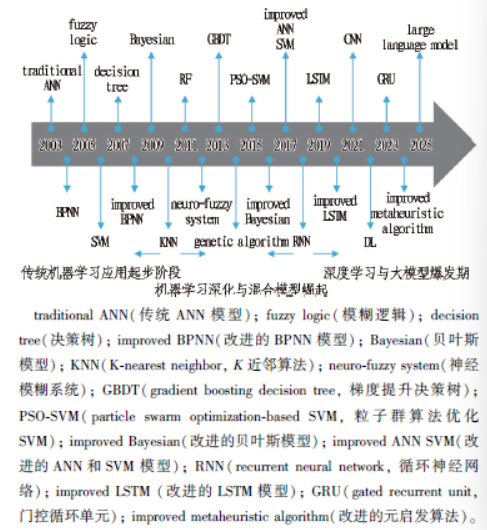
图3 ML 的时序演化图
2 ML 在隧道全生命周期的应用进展
ML 在隧道工程领域的应用研究,正围绕围岩识别-掘进优化-健康监测这一核心应用链条展开深度探索,形成覆盖隧道施工全过程控制与运营期结构健康监测的完整技术体系。在隧道施工阶段,围岩的地质类型、力学参数(如弹性模量、抗压强度)及受扰动后的稳定性,直接决定施工方案的安全性与经济性。因此围岩识别成为链条的首要环节,需通过ML 模型精准提取地质特征、量化力学参数并评估潜在风险,如图4(a)所示。基于围岩识别结果,掘进优化环节进一步利用ML 分析盾构、隧道掘进机等设备的运行参数与地质条件的动态关联,对施工期间造成的地表沉降进行监测和控制、对掘进参数进行实时预测与优化、对能耗进行预测与控制,如图4(b)所示。当隧道进入运营阶段,健康监测环节依托ML 对衬砌缺陷及结构收敛等关键指标进行持续监测与预测,保障隧道长期安全服役,如图4(c)所示。
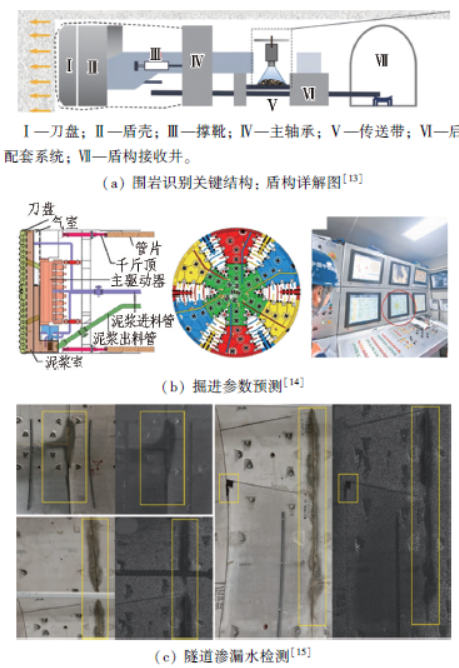
图4 ML 在隧道中的应用
2. 1 ML 在围岩识别中的应用
围岩识别作为隧道工程围岩识别-掘进优化-健康监测全链条的首要环节,其准确性直接影响后续施工参数优化与长期运营安全。近年来,ML 技术在围岩分类、岩石力学参数预测和危险性分析3 个关键方向取得了显著进展。ML 在围岩识别中的应用如表1所示。由表可知: 当前研究主要采用集成学习和DL算法,输入参数呈现多源融合趋势,包括机器运行参数、地质勘探数据和图像特征等。
2. 1. 1 ML 在围岩分类中的应用
在围岩分类领域, Liu 等开发的AdaBoost -CART 集成模型在3332 组操作段数据中实现了0. 8650 的准确率, 较标准CART 模型( 准确率=0. 7530)性能提升显著,证明了集成学习在处理掘进数据中的优势。
Hou 等 基于7 538 个掘进数据样本构建的堆叠集成分类器,通过合成少数类过采样技术将少数类围岩的召回率提升了15% ~20%,有效解决了样本不平衡问题。
Chen 等 创新性地将CNN 应用于隧道工作面地质图像分析,利用42400 张图像实现了岩石结构的自动分类,为传统依赖人工经验的围岩识别提供了新范式。
2. 1. 2 ML 在岩石力学参数预测中的应用
岩石力学参数预测研究呈现出算法复杂度与数据规模的协同演进特征。Sonmez 等开发的二值化多
层神经网络模型基于609 组岩石样本, 实现了R2(决定系数)= 0. 8200 的预测精度,其提出的经验公式为围岩变形模量估算提供了新方法。
Mahmoodzadeh 等对比研究表明,高斯过程回归在170 组伊朗岩石数据中达到R2 =0. 9955 的预测精度,验证了复杂模型对非线性关系的强大拟合能力。但需指出,不同研究间数据标准差异导致模型泛化受限,这成为制约技术推广的主要瓶颈。
2. 1. 3 ML 在危险性分析中的应用
危险性分析领域的发展凸显了动态风险评估的趋势。Li 等基于贝叶斯网络构建的岩爆预测模型(错误率0. 0815)通过敏感性分析识别最大切向应力为关键参数,其处理缺失数据的能力(135 组含缺失案例)具有工程实用价值。
Liang 等采用多种集成学习方法进行短期岩爆风险预测,基于93 组微震监测数据构建模型,结果显示RF 的平均准确率达0. 8000,而GBDT 在高风险案例中准确率高达0. 9167,反映了集成模型在分类任务中的优越性。
2. 1. 4 ML 在围岩识别中的应用特征总结与现存挑战
结合对现有研究的综合分析,围岩智能识别领域的模型应用呈现出与数据规模及问题复杂度高度相关的规律性特征。
在输入参数方面,研究正从单一的静态地质参数向地质-施工-监测多源融合的方向发展,动态参数与静态参数的综合考量成为提升模型性能,特别是动态风险评估准确性的关键。
在模型选择与数据规模的关系上,呈现出明确的对应关系: 小样本数据场景(通常指百级样本量)下,集成学习(如RF、GBDT)和贝叶斯网络表现稳健,因其能有效克服过拟合并具备一定可解释性;而对于大样本数据(千级以上)或特征复杂的问题(如图像、时序信号),DL(CNN、LSTM)及其混合模型展现出更强大的非线性拟合和特征挖掘能力。
表1 ML 在围岩识别中的应用
然而,该领域普遍面临数据匮乏的瓶颈,尤其是掘进优化中的地质参数。隧道掘进中的数据稀疏如图5所示。
图5 隧道掘进中的数据稀疏
地质参数通常通过钻孔获取,区间内的地质情况往往根据有限的钻孔数据进行分析,存在严重的数据稀疏现象;同时,不同工程数据集之间存在显著差异,严重制约了模型的泛化能力和跨项目可比性。
未来研究需着力于突破跨模态数据融合技术、构建数据标准化生态体系以整合和利用不断产生的施工数据,并推动ML 模型的实际应用与推广。
2. 2 ML 在掘进优化中的应用
在隧道工程围岩识别-掘进优化-健康监测的全生命周期核心应用链条中,掘进优化是衔接前期地质认知与后期结构安全的关键环节。其核心目标是基于围岩识别环节输出的精准地质参数(如围岩类型、力学特性、风险等级等),通过ML 技术实现掘进过程的动态调控与参数优化。例如: She 等通过MOTabNetY 模型预测单轴抗压强度和岩石质量指标,将预测结果应用于MOTabNetO 模型以预测掘进速率和每米刀具消耗量,其准确率分别达到0. 9524 和0. 9740,显著优于传统模型,为健康监测阶段奠定结构稳定性基础。
ML 在掘进优化中的应用如表2 所示。由表可知:当前研究主要聚焦于掘进参数与地表沉降预测和能耗优
化,呈现出算法复杂化与数据融合深度化的显著特征。
表2 ML 在掘进优化中的应用
2. 2. 1 ML 在掘进参数预测中的应用
在掘进参数预测中,优势模型趋向于混合模型和DL 模型。Armaghani 等开发的通过PSO 优化ANN
权重的PSO-ANN 模型(测试集R2 =0. 9610),其均方根误差(0. 0220 m/ h)和变异系数(0. 9615)指标均优于传统ANN(R2 =0. 9390),验证了元启发式算法在参数优化中的有效性。
Zhou 等进一步引入贝叶斯优化框架, 使XGBoost 模型的预测精度提升至R2 = 0. 9806,体现了超参数自动调优对模型性能的增益作用。
值得注意的是,遗传编程模型在Zhou 等的研究中表现出更强的非线性处理能力(测试均方根误差=0.038 8 m/ h,ANN 的均方根误差=0. 0472 m/ h),揭示了符号回归在复杂地质-机械关系建模中的潜力。
Gao 等构建的LSTM 网络(均方根误差=1.2610 mm/ min)通过记忆单元捕获掘进参数的长期依赖关系,性能超越传统时间序列模型ARIMAX。
Shan 等基于短输入RNN 构建的掘进速率预测模型的R2 达到0. 8308,展现了DL 的长时程预测稳定性、地质泛化能力和时序特征提取优化,但存在时间滞后现象。
Feng 等使用的深度信念网络在石灰岩段预测中达到R2 =0. 9370,验证了深度置信网络在处理时序机械数据与地质参数耦合关系中的优势。
Gokceoglu 等利用FCM 增强地质特征表征,使RF-FCM 混合模型在岩性交替地层的预测准确率达到0. 712 6,解决了传统ANN 在岩性交替地层中预测不稳定的问题。
Kilic 等采用Optuna 框架对随机森林进行1000 次超参数自动调优,在微盾构数据中实现刀盘转速预测R2 =0. 9600 且推理耗时仅0. 35 s,证明了自动化调参在实时控制系统中的实用性。
2. 2. 2 ML 在地表沉降预测中的应用
地表沉降预测研究呈现出从传统神经网络向深度架构演进的趋势。Chen 等的对比研究表明,广义回归神经网络(平均绝对误差=1. 10 mm)凭借固定网络结构和快速收敛特性,在200 组工程数据中显著优于BPNN(误差降低约30%),揭示了网络结构简化对工程实用性的价值。
Mahmoodzadeh 等通过对比7 种智能方法,发现深度神经网络达到R2 = 0. 9939 和均方根误差=3. 396 mm,显著优于LSTM、KNN 等其他方法,证明了深度神经网络能够高效处理隧道宽度、深度、土壤凝聚力等多参数非线性关系,解决了传统经验公式在复杂地质条件下的局限性。
值得注意的是,Moghtader 等采用BPNN 通过敏感性分析量化了各参数影响权重,同时处理盾构操作参数与地质参数,在测试集达到R2 =0. 9800 的结果。
2. 2. 3 ML 在能耗优化中的应用
在隧道工程掘进优化环节的能耗优化研究中,ML通过挖掘盾构、隧道掘进机等设备运行参数(如刀盘转速、推力、转矩)与地质条件(如围岩岩性、抗压强度)、隧道几何参数(如隧道深度、断面尺寸)间的非线性耦合关系,构建多模态预测模型及混合优化模型,旨在对刀盘驱动系统、整机运行等关键能耗环节的精准预测与动态调控,以期达到降低设备无效能耗并提升施工能效,为绿色隧道施工提供数据驱动支撑。Elbaz等创新地将k-means 聚类与CNN-LSTM 架构结合(R2 = 0. 9800),通过卷积核提取地质参数的空间特征,再经LSTM 分析时序机械数据,实现了能耗预测的多模态融合,为异构数据处理提供了新范式。
2. 2. 4 ML 在掘进优化中的应用特征总结与现存挑战
当前研究呈现出3 方面规律性特征: 1)输入参数从单一机器参数向地质-机器-几何多源融合演变,如She 等整合了岩体质量指标、盾构缸压力等12 维特征,尹玉林等将地质参数和机器参数结合对掘进参数进行优化; 2)模型架构趋向层次化,底层特征提取(CNN/ 聚类)与高层时序分析(LSTM/ GRU)的协同成为主流; 3)数据规模与算法复杂度呈正相关,百级样本量下优化后的集成学习(XGBoost/ RF) 表现稳健,而千级以上数据深度神经网络优势显著。未来研究需着力解决实时预测滞后、跨项目泛化等工程瓶颈,推动算法从实验室高精度向现场高鲁棒性转化。
2. 3 ML 在健康监测中的应用
在隧道工程围岩识别-掘进优化-健康监测的全生命周期链条中,健康监测作为保障长期运营安全的核心环节,其技术发展呈现出多维度智能化的显著特征。健康监测获取的运营期多源数据,又有望反向修正和验证围岩识别模型的泛化能力,优化掘进参数的动态适配性,最终实现数据驱动-模型优化-工程应用-数据反馈的良性循环。ML 在健康监测中的应用如表3 所示。由表可知,当前研究主要聚焦于衬砌缺陷检测和结构安全评估2 个方向。
2. 3. 1 ML 在衬砌缺陷检测中的应用
衬砌缺陷检测领域呈现出高精度-实时性-轻量化协同发展的技术路线。例如: Zhou 等改进的YOLOv4-ED 模型通过引入深度可分离卷积,在保持0. 8184 平均精度的同时将模型体积压缩至49. 3 MB,实现了移动端部署的突破; Xue 等采用的Mask R-CNN(交并比=0. 7800)在水渗漏识别中取得较好效果; Zhao等改进的Mask R-CNN 在隧道渗漏水实例分割中达到准确率为0. 9545、F1 分数为0. 9420、交并比为0. 8970,较全卷积网络和传统算法(如区域生长)提升超过15%。
表3 ML 在健康监测中的应用
2. 3. 2 ML 在安全评估中的应用
安全评估研究凸显了SVM 及其优化变体的工程适用性。Mahdevari 等构建的SVM 收敛预测模型(R2 =0. 9410)通过核函数映射处理地质参数非线性关系,验证了SVM 在处理非线性地质参数与收敛关系中的高效性; Zhou 等进一步引入鲸鱼优化算法改进SVM,使分类准确率达到0. 9565,显著优于传统SVM(0. 8700)、ANN(0. 826 0)和高斯过程(0. 6960)。
此外, Njock 等对大语言模型BERT(bidirectional encoder representations from transformers)的轻量级变体DistilBERT 进行了微调,即DistilBERTTunnelRisk模型。将其用于隧道风险评估, 并与GPT-4 和DeepSeek 这些大语言模型进行比较。结果显示,DistilBERT-TunnelRisk 的精确率、召回率、F1 分数均处于0. 960 0~1. 000 0,无显著性能短板。在置信度方面,高风险等级置信度高达0. 8500。各项数据均远优于GPT-4 和DeepSeek。
2. 3. 3 ML 在健康监测中的应用特征总结与现存挑战
当前健康监测技术呈现3 大规律: 1)模型专业化,针对具体问题发展出缺陷检测(CNN)和风险评估(SVM、DistilBERT-TunnelRisk)的专用架构; 2)精度-效率平衡,轻量化技术(如模型剪枝、量化)使DL 模型推理速度提升3~5 倍; 3)参数的时空特性显著,但仍存在实时预警系统缺失(现有模型响应存在较大延迟)、长期性能预测不足(误差累积导致模型精度下降)等挑战,未来需结合数字孪生技术实现动态更新与跨期验证。数据集大小与优势模型的关系表现出大样本情况下DL 和集成学习模型优势明显。此外,大语言模型逐渐显示出其在风险预测中的潜力,但目前相关的研究不多。在未来的研究中,大语言模型仍有待进一步开发和利用。
综上,围岩识别-掘进优化-健康监测这一核心应用链条,贯穿了隧道工程从施工准备到长期运营的全生命周期,而ML 技术则成为串联链条各环节的关键支撑。在围岩识别环节奠定的地质与风险基础,为掘进优化提供了精准的参数调整依据。掘进优化实现的高效安全施工,又为健康监测阶段的结构稳定性奠定了工程基础; 同时,健康监测获取的运营期结构数据,还可反向反馈至前期环节,用于优化ML 模型的泛化能力与施工参数的适配性,形成数据驱动-模型优化-工程应用-数据反馈的良性循环。这种全链条、一体化的ML 应用模式,不仅解决了隧道工程中传统方法难以应对的高维非线性问题,更推动隧道工程从经验驱动向数据驱动的智能化转型,为复杂地质条件下隧道工程的安全、高效、可持续建设与运营提供了全新技术路径。
3 ML 在隧道工程应用中的关键挑战
ML 在隧道工程围岩识别-掘进优化-健康监测全生命周期应用中虽成效显著,但从技术落地与规模化推广视角看,仍面临多维度瓶颈。在围岩识别环节,动态施工扰动导致数据缺失、不连续,且不同工程数据集标准差异大,严重制约模型泛化能力。掘进优化阶段,实时预测存在时间滞后问题,跨地质条件与施工工况的模型迁移适配性不足,同时多源异构数据融合深度不够,难以充分挖掘数据价值。健康监测领域,实时预警系统响应仍存在较大延迟,长期性能预测中误差累积导致预测精度严重下降。综合来看,这些问题集中体现在数据、模型、工程适配3 个层面,具体关键挑战如表4 所示。
表4 ML 在隧道工程应用中的关键挑战

以上数据、模型、工程适配层面的瓶颈,本质是ML 技术与隧道工程实际需求的适配鸿沟,需从技术突破、体系建设、价值延伸3 个层面提出系统性解决方案,推动ML 在隧道工程的实用化落地。
4 ML 在隧道工程中未来发展方向
针对上文提出的数据质量差、模型黑箱化、工程适配弱等挑战,本文为ML 在隧道工程中应用的进一步研究提出以下建议。
4. 1 数据层面发展方向
4. 1. 1 数据标准化生态体系
标准不统一是制约模型泛化的主要瓶颈。数据标准化生态体系如图6 所示。建议从3 个层面建立数据生态以解决标准不统一问题。
1)制定隧道工程数据采集标准。统一地质参数(如岩石质量指标)、施工参数(如推力)和监测指标(如收敛变形)的测量规范,统一数据接入格式与采集频率。
2)统一数据处理规则。为缺失值、异常值处理等常见数据处理方式设立统一标准,如在缺失值处理时,数值型字段用“中位数”填充,类别型字段用“众数”填充等。
3)统一数据模型与存储格式。
此外,开发数据质量评估程序,对数据质量和标准进行管控。建立一套自动化流程,排除人为干扰因素,增加数据的可信程度。对于数据稀疏,考虑采用多手段结合的方法对数据进行补充。如稀疏的钻孔地质参数,可以通过地震波对地层情况进行检测,补充钻孔之间的地层情况。
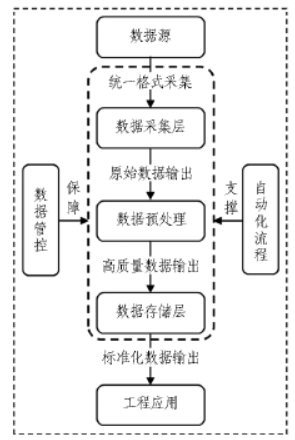
图6 数据标准化生态体系
4. 1. 2 开放数据平台
搭建开放数据平台,整合如Chen 等使用的42400 张地质图像、Zhou 等收集的1500 张衬砌缺陷图像等典型数据集,打破数据孤岛,推动跨项目数据共享。
4. 1. 3 多模态数据融合框架
当前隧道工程数据呈现多源异构特征,但融合深度不足。建议开发专门针对隧道工程特点的多模态融合框架,重点解决如下关键问题。
1)时空对齐。通过动态时间规整等技术,实现地质勘探数据(低频静态)与施工数据(高频动态)的时标同步。
2)设计基于注意力机制的特征融合网络。借鉴Elbaz 等提出的KCNN-LSTM 架构经验,自动学习不同模态数据的贡献权重。
3)探索知识图谱技术在跨领域数据语义关联中的应用。构建包含地质术语、施工参数和监测指标的本体集合,实现数据层面的语义互操作。
目前,关于多源异构数据的研究多集中于将地质数据、机器数据和几何数据结合,很大程度上提高了ML 模型的稳定性和泛化能力,弥补数据缺失。未来,多源异构数据融合还可以考虑地质参数、机器参数和图像参数的结合,如图7 所示。优势在于图像参数能够提供更多的信息,且实时图像数据也具有时序特征,便于处理。
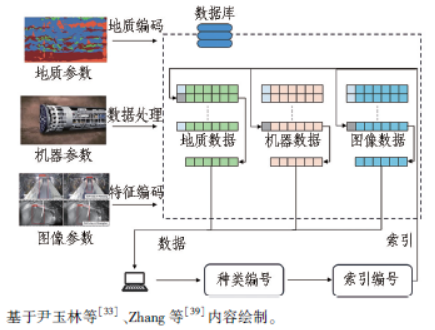
图7 多源异构数据融合在隧道中的应用
4. 2 模型层面发展方向
4. 2. 1 模型可解析性
开发和利用可解释性强的ML 模型或解释工具,让工程人员理解模型决策过程和依据,增强对模型的信任度,促进ML 在隧道工程中的广泛应用。建议从如下方向提升模型的可解析性。
1)专家知识。在某铁路隧道衬砌缺陷预测中,基于沙普利可加解释值的可视化工具帮助工程师定位关键影响因素,使模型采纳率提升。
2) 模型结构设计。Yu 等提出的白盒Transformer 模型CRATE ( coding rate reduction transformEr),通过目标函数拆解-模块数学化-参数意义绑定的全链路设计,让模型的每一层、每一个操作都有明确的数学解释和优化动机,最终实现全白盒化。
3) 解释工具融合。通过融合LIME ( local interpretable model-agnostic explanations)、SHAP(shapleyadditive explanations) 等解释工具,提高模型的可解析性。
4)跨模态解释逻辑。提出基于交替生成对抗学习的多模态表征学习及融合框架,通过跨模态表征融合模块实现模态间度量结构的一致性对齐,在类注意力网络中使不同模态的度量结构达到相互一致,显著提升多模态融合性能。
4. 2. 2 不确定性量化
通过量化模型预测结果的不确定性,为工程决策提供更全面的信息。例如: 在预测隧道衬砌缺陷时,贝叶斯与DL 模型结合不仅给出缺陷位置概率图,还通过预测区间量化置信度,使维护决策的可靠性提升 。
4. 2. 3 大语言模型深化应用
大语言模型凭借其对非结构化文本的深度理解、多模态信息整合及知识生成能力,正成为突破传统ML 局限的关键方向。当前Njock 等的研究已验证轻量级变体(distilBERT-tunnelRisk)在隧道风险评估中的优势,但该技术在围岩识别-掘进优化-健康监测全生命周期中的应用仍处于起步阶段,可以从多个维度进行深化优化,推动其与工程需求的深度适配。下文简要介绍应用场景深化的方向和思路。
1)围岩识别。基于地质勘察报告文本和图像,生成岩性分类报告;结合知识图谱预测潜在风险(如断层破碎带)。
2)掘进优化。实时分析时序数据和施工日志,生成参数调整建议;预测能耗峰值,提出节能方案。
3)健康监测。输入衬砌缺陷图像和监测数据,生成缺陷分析报告;结合历史维修记录,推荐最优维修策略。
4)全生命周期协同。整合各环节数据,生成全周期健康报告。在全周期协同场景中,模型可分析健康监测阶段的衬砌开裂数据,反向追溯施工阶段的围岩识别结果与掘进参数记录,查找原因与提出解决方案,推动全链条数据的闭环优化。
4. 3 工程适配层面发展方向
4. 3. 1 轻量化部署
通过模型压缩、结构优化与硬件适配,使复杂ML算法能在移动端、边缘设备等资源受限环境中高效运行。典型方法包括剪枝减少冗余、量化降低计算内存,推动模型从实验室高精度转向工程实用化。
4. 3. 2 模型优化
模型优化主要通过补充相关规律或信息、跨场景应用以及减小模型本身缺陷和不足等方向进行。结合现有技术及研究趋势分析,建议从如下方向进行模型优化。
1)自适应优化。通过人工智能与ML 技术采集分析数据及偏好,构建动态模型,根据差异调整学习内容、路径与资源以优化效果。
2)物理机制与数据融合的混合优化。以物理信息神经网络为典型,将控制方程作为软约束嵌入神经网络的损失函数中,在复杂系统求解中展现优势。
3)跨场景迁移优化。从数据或任务相关的源场景(源域)迁移知识至目标场景(目标域),以提升目标场景的学习效率,常用方法包括领域自适应技术、跨域强化学习迁移及多任务学习、自监督迁移等。
4. 3. 3 鲁棒性优化
针对参数不确定性,通过定义不确定性集合,将优化目标转化为最小化最坏不确定性下的成本/ 风险,确保决策在未知扰动下稳定有效。主要包括基于矩不确定性的分布鲁棒优化和基于支持集的鲁棒优化2 种方法。
4. 3. 4 跨学科协作
跨学科视角对于推动ML 技术在隧道工程中的应用与发展中至关重要。隧道工程的复杂性要求地质学家提供精准的地层特征与地质参数,工程师贡献施工工艺与结构安全的专业经验,计算机科学家负责算法优化与模型构建,三者的深度合作能够有效解决数据质量参差不齐、模型与工程需求脱节等问题,促进ML技术从理论研究向工程实践的转化。
此外,还可结合国家发展需求,从可持续发展入手,通过ML 技术优化隧道施工方案和运营管理策略,降低能源消耗和环境影响,进一步加强ML 技术应用与隧道工程领域的竞争力。
5 结论与建议
1)ML 在隧道工程围岩识别-掘进优化-健康监测全生命周期应用成效显著,不同算法在各环节优势突出。集成学习与DL 大幅提升了围岩分类精度,ANN成为岩石力学参数预测的主流方法,LSTM 和XGBoost在掘进优化中表现优异,DL 在衬砌缺陷检测方面优势明显,SVM 及其变体在运营安全评估中稳定性较强。大语言模型变体在安全评估中表现较好,展现出强大的潜力。
2)围岩识别-掘进优化-健康监测全生命周期链条是ML 实现系统性应用的核心载体。该链条贯穿隧道施工筹备至长期运营的完整流程,各环节环环相扣、协同联动,形成数据驱动的闭环管理体系。施工前期,围岩识别依托集成学习与DL 整合多源数据,为掘进施工提供地质与风险依据,解决传统人工识别弊端。掘进优化阶段,混合模型与时序模型挖掘参数关联实现实时调控,施工数据还能反哺围岩识别模型提升泛化能力。运营期,健康监测借助相关算法实现风险预警与状态评估,其数据可反向优化前期模型与参数适配逻辑,推动隧道工程全流程智能化升级。
3)ML 为隧道工程智能化提供新范式的同时,仍面临多重挑战。数据层面,存在地质勘探数据稀疏、施工监测数据有噪声、运维数据动态性不足等问题,导致模型训练数据质量参差不齐。模型层面,多数复杂算法如DL 存在“黑箱”特性,可解释性弱,工程人员难以理解其决策逻辑。工程适配层面,轻量化部署,健康监测实时预警系统无法满足工程现场实时决策需求等问题仍然存在。
未来ML 在隧道工程中的发展应着力构建数据-模型-工程协同创新体系: 在数据层面,需建立标准化数据生态,统一地质勘探、施工监测等多源异构数据的采集与存储规范; 在模型层面,重点突破轻量化部署( 如模型剪枝、量化) 与可解释性增强,优化LSTM 等时序模型的实时预测能力,同时推进大语言模型在隧道工程的应用; 在工程适配层面,通过跨学科协作推进ML 在隧道工程的应用,并在国家重大工程中验证围岩识别-掘进优化-健康监测全链条的智能化闭环。